Endnoten
[1]
Vgl. K. Laisiepen, E. Lutterbeck, K. H.
Meyer-Uhlenried (Hrsg.):
Grundlagen der praktischen Information und
Dokumentation, S. 27-36.
[2]
Vgl. v.Vf.: Heidegger
über
Sprache und Information.
[3]
Als einführende
Darstellung vgl. A. Diemer: Elementarkurs
Philosophie. Hermeneutik. Als
grundlegende Erörterung einer
philosophischen Hermeneutik vgl.
H.-G. Gadamer: Wahrheit und Methode.
Ferner H.-G. Gadamer. G. Boehm
(Hrsg.): Seminar: Philosophische
Hermeneutik; H.-G. Gadamer: Art.
Hermeneutik, in: J. Ritter (Hrsg.):
Historisches Wörterbuch der
Philosophie, Bd. III; O. Pöggeler:
Hermeneutische Philosophie; H.
Birus (Hrsg.): Hermeneutische Positionen.
Als Einführung in
englischer Sprache R. E. Palmer:
Hermeneutics. Als umfassende
systematische Bibliographie vgl. N.
Henrichs: Bibliographie der
Hermeneutik und ihrer Anwendungsgebiete
seit Schleiermacher.
[4] Die Weichen für
diesen Dialog
lagen bereits bei L.
Wittgenstein vor. Vgl. R. Zimmermann:
Wittgenstein zwischen
Hermeneutik, Phänomenologie und
analytischer Systematik. Ferner
die Proceedings des III. Int. Kolloquiums
"Knowledge and
Understanding". In: Dialectica 33 (1979)
3/4 (darin insbesondere der
Beitrag von R. Rorty: De l'épistemologie à
ll'hermeneutique, der einige Thesen seines
Buches: Philosophie and the
Mirror of Nature, aufgreift), sowie die
Stellungnahmen H.-G. Gadamers
in seinem Werk: Wahrheit und Methode, S.
513 ff. Zum Gegensatz
"verstehen/erklären" vgl. M. Riedel:
Verstehen oder erklären?
Zur Theorie und Geschichte der
hermeneutischen Wissenschaften. Ferner
F. M. Wimmer: Verstehen, Beschreiben,
Erklären. Zur Problematik
geschichtlicher Ereignisse; G. Pasternack:
Philosophische Hermeneutik
und materiale Hermeneutik. Vgl. auch G.
Floistad (Hrsg.), Contemporary
philosophy.
[5] Hier könnte ein
Dialog mit der
Marxistischen Dialektik
anknüpfen. Vgl. z.B. in Zusammenhang mit
der Frage nach der
Technik
D. Ihde: Technics and Praxis, S. XXIV ff.
Ideologiekritisch
bezüglich eines methodischen
Universalitätsanspruches der
Hermeneutik J. Habermas: Der
Universalitätsanspruch der
Hermeneutik. Vgl. auch A. Diemer:
Elementarkurs Philosophie, S. 106
ff., der bei Marx sowohl einen "anti-" als
auch einen
"pro-hermeneutischen" Ansatz aufzeigt.
Vgl. dazu G. Petrovic: Der
Spruch des Heidegger, sowie die Ansätze zu
einer
"materialistischen Hermeneutik" bei Th.
Metscher: Grundlagen und
Probleme einer materialistischen
Hermeneutik der Literatur.
[6] Zur Geschichte
des
Verstehensbegriffes vgl. K. O. Apel: Das
Verstehen. Zum Begriff des Verstehens als
Grundlage einer "rationalen
Hermeneutik" vgl. D. Hirschfeld:
"Verstehen" als Synthesis: die
evolutionäre Form hermeneutischen Wissens.
[7] In Anlehnung an A.
Diemer: Elementarkurs
Philosophie, S. 122 ff.
Das Wort "Vorverständnis" findet man bei
Heidegger in seinen
frühen Vorlesungen. Vgl. M. Heidegger:
Prolegomena zur Geschichte
des Zeitbegriffes, S. 414. Vgl. auch R.
Bultmann: Das Problem der
Hermeneutik.
[8] A. Diemer:
Elementarkurs
Philosophie, S. 124.
[9] Vgl. N. Henrichs: Das
Problem des
Vorverständnisses.
[10] K. R. Popper:
Objective Knowledge, S.
345, 162 ff. In seiner
objektivistischen Hermeneutik betont
Popper einseitig die "Autonomie"
der "Denkinhalte" (vgl. unten II, 1, c).
Zu Poppers Hermeneutik vgl. J.
Farr: Popper's Hermeneutics, und die
Kritik von K. O. Apel: Comments on
Farr's Paper. Ferner G. Radnitzky:
Contemporary Schools of Metascience
(insbes. Bd. 2). Davon sind die Ansätze zu
einer "objektiven
Hermeneutik" zu unterscheiden, die, im
Gegensatz zur
positivistisch-rationalistischen
Denktradition, "objektive soziale
Sinnzusammenhänge" herauszuarbeiten
versuchen. Vgl. H. J. Wagner:
Wissenschaft und Lebenspraxis. Das Projekt
einer "objektiven
Hermeneutik", sowie U. Matthes-Nagel:
Latente Sinnstrukturen und
Objektive Hermeneutik.
[11] W. Wieland:
Möglichkeiten der
Wissenschaftstheorie, S. 36 ff.
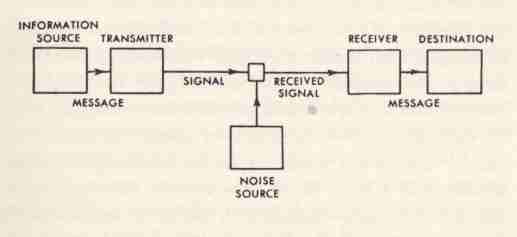
[12] Ebd. S. 42
[13] Vgl. W. Stegmüller:
Metaphysik, Skepsis,
Wissenschaft, S. 362
ff.
[14] K. O. Apel:
Szientismus oder
transzendentale Hermeneutik?; ders.:
Transformation der Philosophie, Bd. 2, S.
215.
[15] Vgl. K. O. Apel:
Reflexion und materielle Praxis,
S. 9 ff.
[16] J. Habermas:
Erkenntnis und Interesse, S. 371.
[17] H.-G. Gadamer:
Wahrheit und Methode, S.
517. Ders.: Vernunft
im Zeitalter der Wissenschaft, S. 78 ff.
Ferner L. K. Schmidt: The
epistemology of H.-G. Gadamer: An analysis
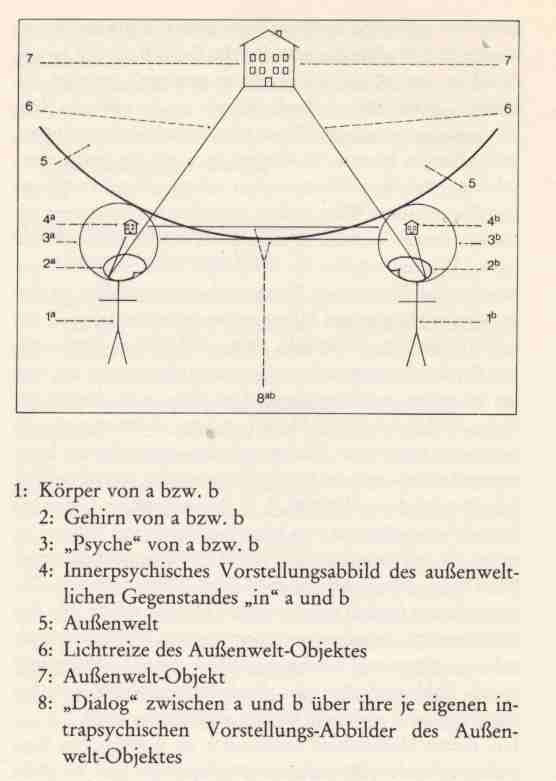
of the legitimization of
Vorurteile.
[18] O. Marquard: Frage
nach der Frage, auf die die
Hermeneutik die
Antwort ist, S. 3
[19] M. Heidegger: Sein
und Zeit, S. 366. Ferner J.
Ritter (Hrsg.):
Historisches Wörterbuch der Philosophie,
Art. Horizont.
[20] H.-G. Gadamer:
Wahrheit und Methode, S.
290.
[21] Zum hermeneutischen
Dreieck vgl. A.
Diemer: Elementarkurs
Philosophie, S. 139 ff. Zum
hermeneutischen Zirkel J. C. Maraldo: Der
hermeneutische Zirkel.
[22] Vgl. N. Henrichs:
Zum Problem des
Vorverständnisses, S. 52.
[23] M. Heidegger: Sein
und Zeit, S. 153.
[24] W. Stegmüller: Der
sogenannte Zirkel
des Verstehens, S. 63-88.
[25] W. Stegmüller:
Walther von der
Vogelweides Lied von der Traumliebe und
Quasar 3 C 273. Betrachtungen
zum sogenannten Zirkel des Verstehens und
zur sogenannten
Theoriebeladenheit der Beobachtungen. S.
82. Vgl. H. Turks' Kritik an
Stegmüller: Wahrheit oder Methode? H.-G.
Gadamers "Grundzüge
einer philosophischen Hermeneutik", S. 140
ff.
[26] Vgl.
K. R. Pavlovic: Science and autonomy: the
prospects for hermeneutic
science; A. Kulenkampff: Art. Hermeneutik; R.
L. Fetz: Kreis des
Verstehens oder Kreis der Wissenschaften?; G.
Radnitzky: Contemporary
schools of Metascience.
[27] G.
Petersen-Falshöft: Die Erfahrung des Neuen,
S. 107. Der Verfasser
analysiert die Herausarbeitung des Vorganges
des Vorverständnisses
durch P. Feyerabend und Th. S. Kuhn.
[28] Ebd.
[29] M. Heidegger:
Sein und Zeit, S. 153: "Man wird jedoch
unter Beachtung, daß
'Zirkel' ontologisch einer Seinsart von
Vorhandenheit (Bestand)
zugehört, überhaupt vermeiden müssen, mit
diesem
Phänomen so etwas wie Dasein zu
charakterisieren." Vgl. ebd. S.
314 ff.
[30] Zu diesen
systematischen Unterscheidungen vgl. A.
Diemer: Elementarkurs
Philosophie..
[31] Vgl. M.
Heidegger: Sein und Zeit, S. 34.
[32] O.
Pöggeler: Heidegger und die hermeneutische
Philosophie, S. 66.
[33] Ebd. S. 365 ff.
Vgl. O. Becker: Größe und Grenze der
mathematischen
Denkweise, S. 169: "Mathematisches und
hermeneutisches Denken stehen
also in einem merkwürdigen Verhältnis der
Komplementarität."
[34] BMFT, Der
Bundesminister für Forschung und Technologie
(Hrsg.:) Programm der
Bundesregierung zur Förderung der
Information und Dokumentation
(IuD-Programm) 1974-1977.
[35] Ebd. S. 18.
[36] Ebd. S. 17.
[37] Ebd. S. 18.
[38] Ebd.
S. 10.
[39] Ebd. S. 26.
[40] BMFT, Der
Bundesminister für Forschung und Technologie
(Hrsg.):
BMFT-Leistungsplan: Fachinformation.
Planperiode 1982-1984.
[41] Ebd. S. 4.
[42] BMFT, Der
Bundesminister für Forschung und Technologie
(Hrsg.)
Fachinformationsprogramm der Bundesregierung
1985-1988. Ferner:
Stellungnahme des Bundesrechnungshofes als
Bundesbeauftragter für
die Wirtschaftlichkeit in der Verwaltung
über die Fachinformation
in der Bundesrepublik Deutschland vom April
1983.
[43] Vgl.
Gesellschaft für Information und
Dokumentation (Hrsg.):
Datenbankführer.
[44] Vgl. J. Koblitz:
Bearbeitung und Verarbeitung von
Fachinformationen. Koblitz bezeichnet
Fachinformation als "eine Art der
gesellschaftlichen Information" (S.
11) mit einer "Fülle möglicher Inhalte"
(z.B. Gesetze,
Theorien, Verfahren, Arbeitsgegenstände,
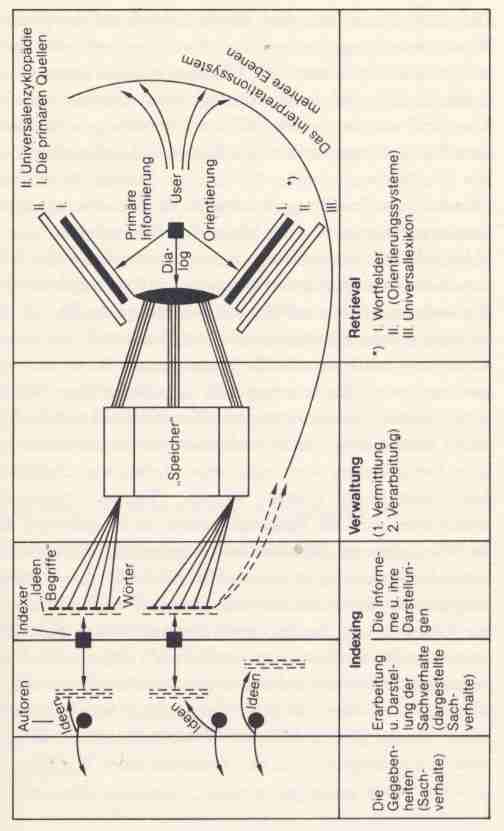
Rechtsnormen) bestimmt,
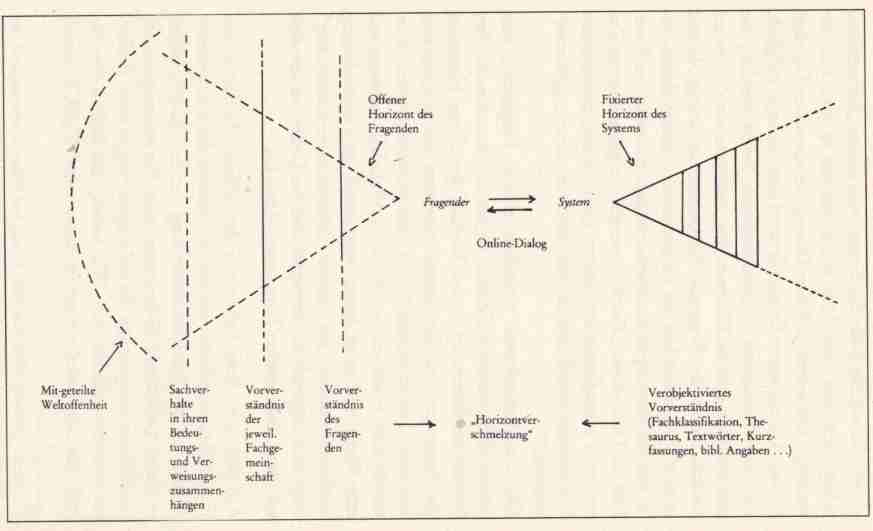
wobei er eine Reihe von (möglichen)
Eigenschaften nennt (S. 11).
Eine weitgehende Übereinstimmung mit
Fachinformation i.w.S. findet
man z.B. bei H. Engelbert: Wissenschaftliche
Informationstätigkeit
und wissenschaftlich-technischer
Fortschritt: "Als Informationen, die
bei ihrem Empfänger bestimmte Fachkenntnisse
voraussetzen und
nicht für jedermann bestimmt sind, bilden
die wissenschaftlichen
Informationen zusammen mit anderen Arten die
Unterklasse der Fach-(Spezial-)informationen.
Die
populärwissenschaftlichen Informationen,
publizistischen,
ästhetischen und Alltagsinformationen wenden
sich dagegen an alle
Mitglieder der Gesellschaft, ohne Rücksicht
auf ihre fachliche
Tätigkeit." (S. 43)
[45] Diese Einsicht
liegt z.B. auch dem bekannten französischen
"Nora-Report"
zugrunde. Vgl. S. Nora, A. Minc: Die
Informatisierung der Gesellschaft,
S. 83 f.
[46] A.J. Mihaijlov,
R.S. Gilarevskij: Zu den
Entwicklungsperspektiven der Informatik.
[47] Bbd. S. 4.
[48]
V.
Giuliano, M. Ernst, J. Dunlop, S.
Crooks (A.D. Little, Inc.): Passing the
Threshold into the Information
Age. Perspective for Federal Action on
Information, Vl. I, S. 20 ff.
[49] Vgl. den
bekannten "Weinberg-Bericht".
[50] Cuadra Ass. Inc.
(Hrsg.): Directory of Online Databases
(1985).
[51] Ebd. S. 6. Die
Termini "Datenbasis" und "Datenbank" werden
hier als synonym gebraucht.
Sie werden aber manchmal in den einzelnen
Sprachen und aus
unterschiedlichen Gesichtspunkten definiert.
[52] Cuadra
Ass. Inc. (Hrsg.): Directory of Online
Databases (1981). Im "subject
index" von Cuadra (1985) werden 342 Gebiete
genannt.
[53] "Partiell" ca.
außer dem allgemeinen Interesse, solche
Bereiche durchaus
fachlich gemeint sein können.
[54] Platon:
Theaitetus 146 d - 147 c: "Gar offen
und freigebig Lieber, gibst
du mir, um eines gefragt,
vielerlei und Mannigfaltiges statt des
Einfachen [...] Es ist also eine
lächerliche Antwort von dem, welcher gefragt
wird, was Erkenntnis
ist, wenn er darauf durch den Namen
irgendeiner Kunst antwortet [...]
Dann auch, obwohl er schlicht und kurz
antworten konnte, beschreibt er
einen unendlichen Weg."
[55] Geläufige
Komposita sind z.B. Facharbeit, Facharzt,
Fachaufsatz, Fachausbildung,
Fachausdruck (-begriff), Fachberater,
Fachbereich (-gebiet, -disziplin,
-studium), Fachbibliographie,
Fachbibliothek, Fachbuch,
Fachgeschäft (-handel), Fachinformation,
Fachjargon (-chinesisch),
Fachkenntnis (-wissen), Fachkommunikation,
Fachkraft, Fachkreis,
Fachliteratur (-publikation), Fachmann (pl.
Fachleute, Fachwelt,
-gelehrte, -referent), Fachpresse,
Fachschule (-hochschule),
Fachsprache, Fachwörterbuch,
Fachzeitschrift.
[56] "Fachsimpeln"
gehört, laut Duden, zur Studentensprache des
19. Jahrhunderts.
"Fachidiot", im sinne des politisch
"Blinden", weist auf den
griechischen Begriff "idiotes", d.h. der
sich auf sein Privatleben
beschränkende an staatlichen Aufgaben
uninteressierte Mensch, hin.
Vgl. J. Ritter (Hrsg.): Historisches
Wörterbuch der Philosophie,
Art. Laie.
[57]
"Fachinformation" kommt weder bei G. Wahrig:
Deutsches Wörterbuch,
noch in "Meyers Enzyklopädisches Lexikon"
vor.
[58] Vgl. J. Grimm,
W. Grimm: Deutsches Wörterbuch; A. Götze
(Hrsg.):
Trübners Deutsches Wörterbuch; M. Lexer
Mittelhochdeutsches
Handwörterbuch; Der Große Duden, Etymologie.
Zum mhd.
Terminus "vach" schreibt Lexer::
"vorrichtung zum aufstauen des wassers
und zum fischfange (mit einem
fanggeflechte), fischwehr [...]; fang
(der vögel), fangnetz, [...]; stück, teil,
abteilung (einer
räumlichkeit, einer wand, mauer, der
rüstung, des schildes,
etc., falte des schleiers, hemdes) eigentl.
u. bildl. (auf das innere
übertragen)". Der Duden und Götze setzen das
18. Jahrhundert
als Übergangszeit für die
Bedeutungsübertragung (hier
eine Metonymie) aus dem handwerklichen
Bereich auf Wissen bzw. auf
Spezialgebiete in Handwerk, Kunst und
Wissenschaft. Diese
Übertragung schließt "an die konkrete
Vorstellung der
Fächer in einem Schrank oder Regal an, die
heute noch lebendig
ist" (Duden). Das Kompositum "Fachmann"
stammt aus dem 19. Jahrhundert.
Jüngere Bildungen, wie "Facharbeiter",
"Facharzt", "Fachschule"
usw. folgten. – In der
Gegenwartssprache lassen sich die
Bedeutungen von "Fach"
folgendermaßen darstellen: 1) Unterabteilung
in einem Raum oder
einer Fläche (z.B. Schrankfach); in der
Weberei: Zwischenraum zw.
den Kettfäden; Mauerstück zw. dem
Balkengefüge
(Fachwerk); 2) Unterabteilung eines Wissens-
oder Arbeitsgebietes
(Studienfach, Lehrfach); vom Fach sein,
Fachmann sein, etwas von einer
Sache verstehen. Entsprechende engliche
Ausdrücke im
Wissensbereich sind z.B. "specialized
field", "scientific and technical
information", "expert", "specialist",
"professional"; und im
Französischen "spécialiste", "spécialité",
"information spécialisé", "homme du metier",
"professionel" usw.
[59] Vgl. J. Austin:
A Plea for Excuses: "[...] a word
never –
well,
hardly ever – shakes
off its etymology and its formation. In
spite of all changes in and
extensions of and additions to its meanings,
and indeed rather
pervaiding and governing these, there will
still persist the old idea
[...]" Zitat nach St. A. Erickson: Language
and Being. An Analytic
Phenomenology, S. 14.
[60] Vgl. die
Platonischen Metaphern in bezug auf den
Erkenntniserwerb. Theaetetus
197 b ff.
[61] W. Schadewaldt:
Die Anforderungen der Technik an die
Geisteswissenschaften, S. 36-68.
[62] Diese
Unterschiede sind z.B. im bibliothekarischen
Bereich üblich. Der
Ausdruck "populärwissenschaftlich" ist z.T.
mit negativen
Konnotationen belastet und wurde durch den
Begriff "Sachbuch"
zurückgedrängt. Vgl. B. Wichert: Die
Annotierung
populärwissenschaftlicher Literatur auf dem
Gebiet der
Naturwissenschaften, die die Einteilung:
Sachbücher,
Fachbücher, wissenschaftliche Literatur
gebraucht, wobei unter
"Fachbuch" ein Buch für die berufliche
Praxis (!) verstanden wird.
[63] In diesem
universalen Sinne verwendet z.B. Diemer den
Begriff "Sachbereich" (vgl.
unten I, 3, b) I. Dahlberg spricht von
"Wissensgebieten". Vgl. I.
Dahlberg: Grundlagen universaler
Wissensordnung.
[64] Ebd.
[65] B. Langefors:
Information Systems.
[66] B. Langefors:
Information Systems Theory. Der Hinweis auf
Carnap bezieht sich auf R.
Carnap: Meaning and Necessity. A Study in
Semantics and Modal Logic.
[67] B. Langefors:
Hermeneutics, Infology and Information
Systems; ders.: Models and
Methodologies.
[68]
Zur
Erläuterung der
"infologischen" Dichotomie beschreibt
Langefors folgende Situation: ein
Techniker beobachtet die Temperatur "a" eines
Kessels in einer
chemischen Fabrik. Er versteht die Bedeutung
von "a", da er die Rolle
des Thermometers im Gesamtzusammenhang der
Apparatur und der Fabrik
kennt. Wenn er diesen Wert einem anderen
(nicht anwesenden)
Fachkollegen mitteilen will, kann er nicht
einfach von "a" sprechen,
sondern muß sich auf den beobachteten
Gegenstand, auf die
Meßskala und auf die Zeit beziehen, bzw.
diesen Zusammenhang
implizit deutlich machen. Nach der formalen
Lösung des Problems
(anhand von Darstellungs- und
Interpretationsregeln) bleibt also das
("informelle") Problem des Verstehens im
Hinblick auf die
Informationsstruktur des Empfängers. Dabei muß
eine
gemeinsame Referenzstruktur im voraus
vereinbart werden. Ebd. S. 7 ff.
[69] In Zusammenhang
mit der Kontroverse, ob die Hermeneutik eine
spezielle Methode der
Geisteswissenschaften ist, betont Langefors,
daß das Verstehen
von Gesetzmäßigkeiten auch ein
hermeneutischer Prozeß
ist. Das Vorverständnis ist keine bloße
Interpolation
zwischen dem Verstehen und den "objektiven"
Fakte, sondern, pace Wittgenstein II, die
Erfahrung
der Fakten selbst ereignet sich nur in
Zusammenhang mit einem
"Sprachspiel". Das Verstehen als
"infologisches Zusammenspiel" bildet
die Bedingung der Möglichkeit dieser Fakten.
Bd. S. 13 ff.
[70] Langefors stellt
die Frage, inwiefern hermeneutisches Denken
zwar nützlich sein
kann aber die entscheidende Frage nach der
Wahrheit (das "validation
problem") nicht zu beantworten vermag.
Umgekehrt stellt er aber die
Frage, wie verifiziertes Wissen im Hinblick
auf seine Nützlichkeit
seine Gültigkeit aufweisen kann. Wenn aber,
nur diejenigen
Auslegungen als "wissenschaftlich"
gekennzeichnet werden können,
die auch als vorläufig gelten (vgl. die
Frage nach der
"Letztbegründung" in der
Wissenschaftstheorie"), dann stellt
gerade die Hermeneutik die Struktur der
kritischen Bewegung der
Reflexion dar. Die Verifikationskriterien
hängen jeweils von der
in Betracht stehenden Sache ab. Die Frage
ist also nicht, ob die
Hermeneutik eine Wissenschaft ist, sondern
ob die Wissenschaft(en) ihre
ihr innewohnenden hermeneutischen Momente
thematisiert. Langefors zeigt
auch, daß die Metapher des "hermeneutischen
Zirkels", z.B. bei
Fragen der Speicherkapazität im Computer,
von Nutzen sein kann
(programmierte Begriffsgenerierung, wodurch
"einfache" Ebenen in
"höhere" überführt werden können).
[71] B. Langefors:
Infological Models and Information User
Views.
[72] Ebd. S. 22.
[73] Ebd. S. 28.
[74] Ebd. S. 29.
[75] Vgl. A.
Diemer: Elementarkurs Philosophie, S. 190
ff.
[76] Vgl.
A. Diemer: Informationswissenschaft. Zur
Begründung einer
eigenständigen Wissenschaft und zur
Grundlegung eines autonomen
Bereiches "Informationswissenschaften".
[77] Vgl. A.
Diemer: Klassifikation, Thesaurus und was
dann?
[78] Vgl. A.
Diemer: "L'ordre (classification) universel
des savoirs comme
problème de philosophie et d'organisation.
[79] Vgl. A. Diemer:
Elementarkurs Philosophie, S. 193.
[80] Vgl. A. Diemer:
Raster zur sachlogischen Klassifizierung des
gesamten Wissens nach
fachlichen und funktionalen Gesichtspunkten
mit hierarchischer
Gliederung für ein universales
Informationsbankensystem.
[81] Vgl. A. Diemer:
Information Science – A New
Science.
[82] Bed. S. 201 ff.
[83] Vgl. N.
Henrichs: Bibliographie der Hermeneutik.
[84] Vgl. N.
Henrichs: Philosophie Datenbank. Bericht
über das Philosophy
Information Center an der Universität
Düsseldorf. Ders.:
Philosophische Dokumentation.
[85] N. Henrichs:
Informationswissenschaft und
Wissensorganisation, S. 161.
[86] Ebd. S. 168.
[87] N. Henrichs:
Hermeneutik. Eine Einführung in die Theorie
der Interpretation
(z.B. von Texten) und ihre
informationswissenschaftliche Relevanz.
[88]
N.
Henrichs: Sprachprobleme beim
Einsatz von Dialog-Retrieval-Systemen, S. 223.
[89] Vgl. N.
Henrichs: Benutzungshilfen für das Retrieval
bei
wörterbuchunabhängigen indexiertem Material.
(Vgl. III, 1, c).
[90] Vgl. H.
Henrichs: Gegenstandstheoretische Grundlagen
der
Bibliotheksklassifikation; ders.:
Sozialisation der Information. Zum
Aufgabenspektrum der
Informationswissenschaft.
[91] Vgl. N.
Henrichs: Von der Dokumentation über die
Information zur
Kommunikation; ders.: Sozialisation der
Fachinformation.
[92] Vgl. E. Oeser:
Wissenschaft und Information. Bd. 2:
Erkenntnis als
Informationsprozeß.
[93] Vgl. I.
Dahlberg: Grundlagen universaler
Wissensordnung.
[94] W. Kunz, H.
Rittel: Die Informationswissenschaften. Ihre
Ansätze, Probleme,
Methoden und ihr Ausbau in der
Bundesrepublik Deutschland.
[95] W. Stock:
Wissenschaftliche
Information – metawissenschaftlich
betrachtet. Eine Theorie der
wissenschaftlichen Information.
[96] G. Wersig:
Informationssoziologie. Hinweise zu einem
informationswissenschaftlichen Teilbereich.
[97] Vgl. Ch. S.
Peirce: On Signs and the Categories, S. 227:
"A sign therefore is an
object which is in relation to its object on
the one hand and to an
interpretant on the other, in such a way to
bring the interpretant into
a relation to the object, corresponding to
its own relation to the
object." Zum Zusammenhang zwischen Peirce
und der Hermeneutik vgl. K.O.
Apel: Der Denkweg von Ch. S. Peirce; ders.:
Transformation der
Philosophie, Bd. 2.
[98]
Vgl. v.Vf. Information. Ein Beitrag
zur etymologischen und ideengeschichtlichen
Begründung des
Informationsbegriffs; ferner: die umfassende
interdisziplinäre
Studie zum Informationsbegriff von F. Machlup
und U. Mansfield (Hrsg.):
The Study of Information. Interdisciplinary
Messages. Dazu v.Vf.
Epistemology and Information Science. Vgl.
auch H. Völz:
Information. Studie zur Vielfalt und Einheit
der Information.
[99] Vgl. v.Vf. Moral
Issues in Information Science. Ders.: Zur
Frage der Ethik in
Fachinformation und -kommunikation; ferner:
G. Runge, R. Capurro:
Ethische Reflexionen zum Datenschutz im
Bereich der Fachinformation
(Vgl. unten III, 3, c)
[100] Zur Rolle der
Peirceschen Semiotik als Grundlage der
Informationswissenschaft vgl.
Ch. Pearson, V. Slamecka: Semiotic
Foundations of Information Science;
außerdem P. Zunde: Predictive Models of
Information Systems.
[101] Vgl. N.J.
Belkin, R.N. Oddy, H.M. Brooks: ASK for
Information Retrieval. Part I.
Background and Theory; N.J. Belkin:
Anomalous States of Knowledge as a
Basis for Information Retrieval; N.J.
Belkin, R.N. Oddy: Design Study
for an Anomalous State of Knowledge Based
Information Retrieval System;
N.J. Belkin: Cognitive Models and
Information Transfer.
[102] G. Wersig hat
die ASK-Theorie als einseitig Nutzer-
anstatt Problembezogen
kritisiert. Inzwischen hat Belkin seinen
ursprünglichen
textbezogenen Ansatz sowohl im Hinblick auf
den Nutzer als auch auf die
zugrundeliegenden Probleme selbst erweitert.
Vgl. G. Wersig: The
Problematic Situation as a Basic Concept of
Information Science in the
Framework of Social Sciences: A Reply to N.
Belkin. Zu Wersigs
kybernetischem Modell vgl. unten II, 1, b.
[103] Vgl. N.J.
Belkin, S.E. Robertson: Information Science
and the Phenomenon of
Information; N.J. Belkin: Information
Concepts for Information Science.
[104] W. Kunz,
H.W.J. Rittel: Die
Informationswissenschaften.
[105] W. Kunz,
H.W.J. Rittel: A System Analysis of the
Logic of Research and
Information Process.
[106] E. Hollnagel:
The Relation between Intention, Meaning and
Action.
[107] Vgl. N.J.
Belkin u.a.: ASK for Information Retrieval,
S. 65.
[108] Vgl. E. Hollnagel:
The paradigm for
understanding in hermeneutics and cognition.
[109] E. Hollnagel:
Is information science an anomalous state of
knoweldge?
[110] Ebd.
[111] Vgl. N.J.
Belkin u.a.: ASK for Information Retrieval.
[112] Vgl. E.
Hollnagel: Is information science an
anomalous state of knowledge? S.
186: "Or one might equally well have turned
of the humanistic sciences,
notable the science of hermeneutics, which
is concerned with the way in
which meaning is interpreted from a text or
message, to find the same
kind of evidence. It may, however, be of
greater value for information
scientists to realize that, even within
their own discipline, such an
undertaking is possible."
[113] Th. S. Kuhn:
The Structure of Scientific Revolutions.
[114] De Mey: The
relevance of the cognitive paradigm for
information science; ders. The
Cognitive Paradigm; ders.: Cognitive Science
and Science Dynamics.
Philosophical and Epistemological Issues for
Information Science.
Sowohl Belkin als auch Hollnagel weisen auf
De Mey hin.
[115]
Vgl. die Untersuchungen H. Stachowiaks, der
folgende Kriterien für
den Modellbegriff aufstellt: jedes Modell
hat eine Abbildfunktion, ist
spezifisch verkürzend und wird pragmatisch
verwendet. H.
Stachowiak: Allgemeine Modelltheorie.
[116] Vgl. H. Diels:
Die Fragmente der Vorsokratiker, Bd. 2, S.
114 ff.
[117] Vgl. Platon:
Theaitetus 220b. Zur Deutung Platons aus der
Sicht der neueren
Wissenschaftstheorie vgl. W. Detel: Platons
Beschreibung des falschen
Satzes in Theätet und Sophistes.
[118] Im
Mittelpunkt der Kritik Platons steht die
Lehre des Protagoras, die
auch von Aristoteles kritisiert wird. Vgl.
M. Heidegger: Aristoteles,
s. 196 ff.
[119] Vgl. v.Vf.:
Information. In bezug auf den Terminus
Information bei Thomas von Aquin
schreibt E. Bloch: "dem entspricht unser
heutiges Wort Information bis
zur Kaufmannssprache hin." E. Bloch:
Zwischenwelten in der
Philosophiegeschichte. Aus Leipziger
Vorlesungen 1950, S. 91.
[120] R. Rorty:
Philosophy and the Mirror of Nature, S. 6
ff.
[121]
Vgl. M. Boss: Grundriß der
Medizin und der Psychologie.
[122] R. Rorty:
Philosophy and the Mirror of Nature, s. 391.
[123] W.
Steinmüller: Eine sozialwissenschaftliche
Konzeption der
Informationswissenschaft.
[124] Vgl. W.
Steinmüller u.a.: Materialien zum
Informationsrecht und zur
Informationspolitik, s. 34.
[125] Vgl.
v.Vf. Information, S. 248 ff, 169 ff.
[126] Ebd. S. 252 ff.
[127] A.D. Ursul:
Information. Eine philosophische Studie. S.
203(meine Hervorhebung!)
[128] H. Engelbert:
Zum Warencharakter der Ergebnisse
wissenschaftlicher Arbeit, S. 41.
Vgl. G. Groß: Zur Entwicklung einer
allgemeinen
Begriffsbestimmung und Konzeption der
Information; außerdem J.
Koblitz: Bearbeitung und Verarbeitung von
Fachinformationen, S. 33 ff.
[129] Vgl. A.
Hellwig: Untersuchungen zur Theorie der
Rhetorik bei Platon und
Aristoteles, S. 59; L.W. Rosenfield:
Aristotle and Information Theory;
außerdem P.R. Penland: Communication
Science.
[130] Aristoteles:
Rhetorica 1358 b.
[131] Vgl.
L.W. Rosenfield: Aristotle and
Information Theory, s. 79: "Meaning in this Greek view
is logically
limited by the constraints of reality. And because it
is so limited,
the meaning of a word also attains a degree of
permanence, in a logical
sense, which is characteristic of denotative
reference."
[132]
Vgl. Aristoteles: De anima 430 a; ders.: De
memoria 450 1.
[133] Vgl.
Aristoteles: De interpretatione 1, 16 a;
ferner die Deutung von M.
Heidegger: Logik. Die Frage nach der
Wahrheit, S. 162 ff.
[134] Vgl.
Aristoteles: Topica 108 a; ders. Sophistici
elenhi I, 165 a; ders.
Ethica Nicomachea 1098 b; ders.: Metaphysica
A, 995 a. Zum gesamten
Themenkomplex I. Düring: Aristoteles.
Darstellung und
Interpretation seines Denkens.
[135] Aristoteles:
Rhetorica 1420 a 8 (εἴρηκα, ἀκηκόατε, ἔχετε, κρίνατε).
[136] C.E. Shannon,
W. Weaver: The Mathematical Theory of
Communication.
[137] N. Wiener:
Cybernetics or Control and Communication in
the Animal and the Machine.
[138] Vgl. v.Vf.
Information, s. 104 ff.
[139] Y. Bar-Hillel:
An Examination of Information Theory, S.
296.
[140] Steve H.
Heims: John von Neumann and Norbert Wiener.
From Mathematics to the
Technologies of Life and Death, S. 303.
[141]
E. Oeser: Wissenschaft und
Information, Bd. 2, S. 60 ff. Vgl. S. Thomas:
Some Problems of the
Paradigm in Communication Theory.
[142] B. Waldenfels:
Der Sinn zwischen den Zeilen; ferner C.F.
Graumann: Interpersonale
Perspektivität und Kommunikation.
[143]
G. Wersig: Information –
Kommunikation –
Dokumentation.
[144] Vgl. G.
Wersig: Ein Kanalmodell als
Grundorientierung in der Fachkommunikation.
[145]
G. Wersig: Neue Dienstleistungen und
Informationsvermittlung-–
Gedanken
zum Modischen in der Information und
Dokumentation, S. 171.
[146] G. Wersig:
Trennen sich die
Wege? Neue Orientierungsmuster der
Informationswissenschaft angezeigt.
[147] C. Cherry: World
Communication: Threat or
Promise? A
Socio-technical Approach, S. 4.
[148] Vgl.
N. Fischer: Die Ursprungsphilosophie in
Platons
"Timaios".
[149] Vgl. v. Vf.
Information, S. 30 ff.
[150] Ebd.
[151] Vgl. F. Nietzsche:
Werke. Vgl. M. Heidegger:
Nietzsche, Bd. I, S.
585 ff.; außerdem W. Kaufmann: Nietzsche, S.
455 ff.
[152] K. R. Popper:
Objective Knowledge. An
Evolutionary Approach. Zu
den folgenden Erörterungen vgl. v.Vf. Zur
Kritik von K.R. Poppers
platonistischem Modell des Wissens; ders.
Epistemology and Information
Science.
[153] K. R. Popper:
Objective Knowledge, S. 154
[154] E. D. Klemke: Karl
Popper, Objective Knowledge,
and the Third
World, S. 46
[155] C.F.
v. Weizsäcker: Naturgesetz und Theodizee, in:
ibid: Zum
Weltbild
der Physik. Stuttgart 1976, S. 160. Weizsäcker
weist auf den
theologischen Ursprung der Vorstellung von
"möglichen Welten" bei
Leibniz hin.
[156] Vgl.
J. W. Grove: Popper "Demystified": The
Curious
Ideas of Bloor (and some Others) about World
3. In: Philosophy of the
Social
Sciences 10, 1980, S. 173-180, der u.a. die
Einwände seitens der
marxistischen
Soziologie zu entkräften versucht.
[157] Vgl. H. Arendt: Vita
activa oder Vom tätigen Leben S. 173: "Der
Hacken ist nur, daß es ebenso unmöglich ist,
aus diesem Feld
des Bewußtseins (...) je in eine Außenwelt zu
kommen, wie
es
unmöglich ist, aus dem Bewußtsein der
Körperfunktionen
sich je eine Vorstellung zu machen, wie ein
Körper,
einschließlich
des eigenen, nun eigentlich in seiner nach
Außen in Erscheinung
tretenden
Gestalt aussieht." Diese
Kritik richtet sich gegen Descartes.
[158] K. R. Popper:
Objective Knowledge, S. 341.
[159] Vgl. M. Bunge:
Treatise on Basic Philosophy.
Vol. 2: Semantics I,
S. 186. "To
call what is known, i.e. knowledge, a world
and assume that it
is
superimposed on the world of fact (Popper,
1968) is an unnecessary
Platonic
fantasy. There is only one world and cognitive
subjects are part of it
and intent on knowing (or ignoring) some
chunks of it [...] There is no
knowledge without both an object of knowledge
and a knowing subject.
The
claim that there is absolute knowledge, or
knowledge in itself, above
and
beyond concrete knowing subjects, is
fantastic. Moreover it violates
the
very syntax of 'to know', for 'x is
known' is short for 'There
is
at least one y such that y is
a knowing subject and y
knows x.' Obliterate mankind and no
human knowledge will
remain."
[160] K. R. Popper:
Objective Knowledge, S. 116
[161] Darauf macht D. Rudd:
Do we really need World
III? Information
science with or without Popper, aufmerksam.
Vgl. K. R. Popper, Objective Knowledge, S.
121: "All
work in science is work directed towards the
growth of objective
knowledge.
We are workers who are adding to the growth of
objective knowledge as
masons
work on a cathedral".
[162] K.R. Popper: Objective
Knowledge, S. 107 ff.
[163] Vgl. M. Bunge:
Treatise, S. 2: "An
uninterpreted language, i.e. a well
constructed system of artificial
signs
with no designata, would be as idle and
unintelligible as a scientific
manuscript after a total nuclear holocaust."
[164] H. Arendt: Vita
Activa, S. 124.
[165] Vgl. E. Oeser:
Wissenschaft und Information, S.
37: "Denn
wissenschaftliche Erkenntnis will 'objektive
Erkenntnis' sein.
'Objektivität
der Erkenntnis bedeutet aber nicht die
Eliminierung des konkreten
erkennenden
Subjekts, denn wissenschaftliche Hypothesen
und Theorien sind stets
Produkte
der Tätigkeit eines Konkreten realen
Erkenntnissubjekts, sondern
'Objektivität'
kann nur Allgemeingültigkeit,
Intersubjektivität oder
bestenfalls
Transsubjektivität bedeutet. Sie kann nicht
durch die
metaphysische
Hypostasierung eines neuen Seinsbereiches,
einer Welt der objektiven
Probleme
und Problemlösungen (K. Popper, Objektive
Erkenntnis, Hamburg
1973,
S. 172 ff.), sondern allein durch die
Verobjektivierung des
erkenntnistheoretischen
Subjekts erreicht werden."
[166]
Vgl. J. Hintikka: Some varieties of
information, S. 179:
"Hence
Popper's
emphasis on boldness as a guide of a
scientist's life is in
reality
predicated on a romantic image of a
brilliant scientist making his
discoveries
against all odds. In the sober daylight of
the actual history of
science,
I am afraid, such an image is bound to
appear as unrepresentative of
the
principles of scientific investigation as
the charge of the light
brigade
is of the principles of twentieth-century
warfare: it's magnificent,
but
it is not science."
[167]
Vgl. B. C. Brookes: The foundations of
information science.
[168]
K. R. Popper: Objective Knowledge, S. 107.
[169]
B. C. Brookes: The foundations of
information science, S. 132.
[170]
Vgl. die Ergänzungen zum Popperschen Modell
durch "kognitive"
Gesichtspunkte bei P. Ingwersen:
Psychological Aspects of Information
Retrieval; ders.: A cognitive view of three
selected online search
facilities. Ferner v.Vf.: Epistemology and
Information Science.
[171]
D. A. Kemp: The Nature of Knowledge. An
Introduction for Librarians.
[172]
Vgl. A. Einstein: Ideas and Opinions, S.
342: "Knowledge
exists in two forms - lifeless, stored in
books, and alive in the
consciousness
of men. The second form of existence is
after all the essential one;
the
first indispensable as it may be, occupies
an inferior position."
[173] Vgl.I. Kant:
Kritik der reinen Vernunft, Vorrede zur
ersten Auflage.
[174] Vgl. H. Arendt: Vita
activa, S. 14.
[175] Vgl. A.
Murguía: Le texte du monde.
[176] Vgl. M. Boss:
Grundriß der Medizin, der das Ergebnis einer
langjährigen
Zusammenarbeit mit Heidegger darstellt.
Diese Ansätze setzen die
bahnbrechenden phänomenologischen Analysen
E. Husserls voraus.
[177] Wenn die
folgende Terminologie vielleicht in mancher
Hinsicht als "zu poetisch"
oder "nicht exakt" anmuten könnte, dann sei
an den "topos" des
Aristoteles, "daß man nicht in allen Dingen
in gleicher Weise
nach Exaktheit streben dürfe" erinnert
(Ethica Nicomachea 1094 b).
Das Quantifizieren soll damit keineswegs
abgewertet werden.
[178] M. Boss:
Grundriß der Medizin, S. 286-287.
[179] H. Arendt:
Vita activa, S. 50.
[180] Bbd. S. 57.
[181] In den Begriff
der "Verborgenheit" soll also nichts
"hineingeheimnist" werden. Man
sollte keine "Geheimnisse" dort suchen, wo
sie nicht zu finden sind.
Das heißt natürlich nicht, daß man die Augen
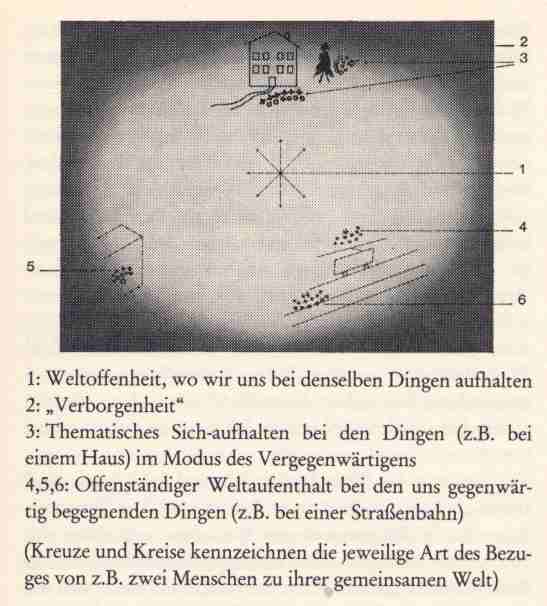
verschließen sollte, wo sie sich vielleicht
zeigen könnten.
Eine solche Haltung gehört, wie Kant uns das
vorgemacht hat, zu
einem wahrhaft kritischen Denken.
[182] M.Boss:
Grundriß der Medizin, S. 244.
[183] Ebd. S. 56. Es
läßt sich dennoch nachweisen, daß der
Informationsbegriff "ursprünglich", d.h.
etymologisch und
ideengeschichtlich, in verschiedenen
Bereichen angesiedelt ist. Vgl.
v.Vf. Information. Eine Verwendung dieses
Begriffs in bezug auf
unterschiedliche Sachverhalte ist von daher
zwar möglich, zumal
wenn Information als logische Kategorie
aufgefaßt wird, es sollte
aber dabei stets auf die Gefahr disparater
Analogien geachtet werden.
Vgl. v.Vf.: Heidegger über Sprache und
Information.
[184] K. Rahner:
Schriften zur Theologie, S. 217
[185] M.
Heidegger, Sein und Zeit, Tübingen 1976,
S. 162: : "Aussagende "Mitteilung", die
Benachrichtigung zum Beispiel,
ist ein Sonderfall der existenzial
grundsätzlich gefaßten
Mitteilung. In dieser konstituiert sich die
Artikulation des
verstehenden Miteinanderseins. Sie vollzieht
die "Teilung" der
Mitbefindlichkeit und des Verständnisses des
Mitseins. Mitteilung
ist nie so etwas wie ein Transport von
Erlebnissen, zum Beispiel
Meinungen und Wünschen aus dem Inneren des
einen Subjekts in das
Innere des anderen. [...] Das Mitsein wird
in der Rede
"ausdrücklich" geteilt,
das heißt es ist schon,
nur ungeteilt als nicht ergriffen und
zugeeignetes." Vgl. H. Lipps'
Kritik der (formalen) Logik (Bolzano, Frege,
Russell) und seine
Auffassung einer hermeneutischen Logik. H.
Lipps: Werke. (insbes. Bd.
II). Ferner J. Hennigfeld: Der Mensch und
seine Sprache. Aspekte der
Phänomenologie bei Hans Lipps.
[186]
M. Heidegger: Sein und Zeit, S. 32.
[187] M. Heidegger:
Prolegomena zur Geschichte des
Zeitbegriffes, s. 373 f. Wenn der
"späte" Heidegger schreibt: "die Sprache
spricht" bedeutet das
m.E. keine Substantialisierung der Sprache,
sondern die
Möglichkeit eines nicht-instrumentalen
Verhältnisses zu ihr:
"Ein Sprechen von der Sprache
könnte nur ein Gespräch sein." M. Heidegger:
Unterwegs zur
Sprache, S. 12, 150. Vgl. v.Vf. Heidegger
über Sprache und
Information.
[188] I. Kant: Was
hießt: Sich im Denken orientieren? A, 325 f.
[189] Vgl. v.Vf.:
Buchkultur im Informationszeitalter.
Überlegungen zum Bezug
zwischen Bibliotheken, Datenbanken und
Nutzern.
[190] Platon:
Phaidros 274 c- 275 b.
[191] H. Arendt:
Vita activa, s. 88.
[192] H:-G. Gadamer:
Wahrheit und Methode, S. 371.
[193] M. Heidegger:
Sein und Zeit, S. 68.
[194] Ebd. S. 69.
[195] Zur Frage nach
der Technik bei Heidegger vgl. D. Ihde:
Heidegger's Philosophy of
Technology; W. Schirmacher: Technik und
Gelassenheit; v.Vf.: Das
Paradigma der technischen Kultur; ders.:
Technics, Ethics, and the
Question of Phenomenology.
[196] H. Arendt:
Vita activa, S. 27.
[197] Ebd. S. 173.
[198] Heidegger
unterscheidet zwischen der
"einspringend-beherrschenden" und der
"vorspringend-befreienden" Fürsorge als zwei
extreme
Möglichkeiten (vgl. Sein und Zeit, § 26).
Für M. Boss
liegt diese letztere der Handlung des
Psychoanalytikers zugrunde. vgl.
M. Boss: Zollikoner Seminare, S. 31. Von
hier aus läßt sich
die "ethische" Frage bei Heidegger anders
stellen als etwa O.F. Bollnow
oder E. Lévinas getan haben.
[199] H.-G.
Gadamer: Vernunft im Zeitalter der
Wissenschaft, S.
101.
[200]
H.-G. Gadamer:
Wahrheit
und Methode. S. 344.
[201] Chr. Wild: Problem, S.
1144
[202] R. Descartes: Regulae
ad directionem ingenii,
Reg. XIII. Gegenüber der Erwartung Descartes
würde den
Menschen mit einem "perfekten Automaten"
identifizieren, findet man im
"Discours de la Méthode" (5e Partie) die
folgende Bemerkung
über den Leistungssinn menschlicher
Sprache:"[...] jamais elles
[d.h. die Maschinen, RC] ne pourraient unser
de paroles ni d'autres
signes en les composant, comme nous faisons pour déclarer
aux autres nos
pensées. Car on peut bien concevoir
qu'une machine soit
tellement faite qu'elle profère des paroles
[...]; mais non pas
qu'elle les arrange diversement pour répondre
au sens de tout ce qui se dira en se
présence, ainsi que
les hommes plus hébétés peuvent le faire."
(Meine
Hervorhebungen!) Es geht u.a. daraus hervor,
daß für
Descartes Maschinen (im Gegensatz zum
Menschen) nicht mitteilen bzw.
(!) denken können, d.h. sie können kein
Gespräch
führen. Man könnte zwar, sagt Descartes, eine
Maschine zu
vorprogrammieren, daß sie Wörter von sich zu
geben vermag,
aber ein solches Reden wäre gerade kein
Gespräch (vgl.
Ausblick).
[203] Vgl. v.Vf.:
Information, S. 181.
[204] Platon: Philebos 58 c.
[205] Vgl. M.
Heidegger: Sein und Zeit, S. 3.
[206] Vgl. S.
Plagemann: Variablen in der
Benutzerforschung; T.D. Wilson: Recent
Trends in User Studies.
[207] Vgl. v.Vf.:
Das Paradigma der technischen Kultur.
[208] J.
Mittelstraß: Zur wissenschaftlichen
Rationalität technischer
Kulturen, S. 64.
[209] Vgl. G. Vowe:
Information und Kommunikation. Brücke
zwischen Wissenschaft und
Gesellschaft; G. Wersig:
Informationssoziologie.
[210] W.
Schadewaldt: Die Anforderungen der Technik,
S. 36 ff. (vgl. I, 2, c).
[211] Vgl. W.
Heisenberg: Der Teil und das
Ganze, S. 247. Ferner die Ausführungen
Platons im Hinblick auf den
"Fachmann" (
Οι σοφοί),
der aufgrund seines Vorwissens, eine
"vor-sichtige" und somit auch
"nützliche" Aussage in bezug auf die Zukunft
machen kann (vgl.
Theaitetus 145 d, 178 a ff)
[212] Eine der
"Haupttugenden" eines Fachmanns, ist die der
Geduld bzw. der
"intellektuellen Geduld mit sich selbst",
wie K. Rahner
anläßlich der Verleihung des
Leopold-Lucas-Preises 1982 (an
der Universität Tübingen) es ausdrückte. Sie
ist das
Eingangstor zur "docta ignorantia" (Nikolaus
von Kues) und
Voraussetzung für weltanschauliche Toleranz.
Vgl. K. Rahner, E.
Jüngel: Über die Geduld, s. l37-63.
[213] Vgl. bei Theophrast:
Charakterbilder, S. 78 f.,
sowie Platon: Hippias minor 368 c.
[214] K.R. Popper:
Conjectures and
Refutations. The
Growth of Scientific Knowledge, S. 67.
[215] Popper
kritisert mit Recht den Szientismus bzw. den
wissenschaftlichen
Dogmatismus positivistischer Prägung, stellt
aber, mit seinem
"Falsifikationismus", neue Kriterien der
Wissenschaftlichkeit auf, die
zu einem "Szientifizismus" führen. P.
Feyerabend und M. Polanyi
haben auf unterschiedliche Weise auf die
Fragwürdigkeit dieses
Ansatzes hingewiesen. Zur Frage nach den
unterschiedlichen
Wissenschaftsgliederungen zum Zwecke der
"Weltorientierung" vgl. K.
Jaspers: Philosophie, S. 128 ff.
[216] Vgl. C.F. v.
Weizsäcker: Zum Weltbild der Physik, S. 266
ff., der in
Anschluß an G. Picht, un dieser wiederum im
Hinblick auf
Aristoteles, Begriffe als Wegweiser deutet.
Grundlegend zum Thema
Fachsprache vgl. W. v. Hahn:
Fachkommunikation. Entwicklung,
linguistische Konzepte, betriebliche
Beispiele. Seine
Begriffsbestimmung lautet: "Fächer sind
Arbeitskontexte, in denen
Gruppen von fachlichzweckrationalen
Handlungen vollzogen werden.
Fachsprachen sind demnach sprachliche
Handlungen dieses Typs sowie
sprachliche Äußerungen, die konstitutiv oder
z.B.
kommentierend mit solchen Handlungen in
Verbindung stehen." (S. 65).
Mit Recht betont der Verfasser, daß es keine
"Fächer per se"
(sowenig wie "Probleme an sich") gibt.
[217] I. Kant:
Kritik der reinen Vernunft, B XIV.
[218] M. Heidegger:
Sein und Zeit, S. 362.
[219] Ebd. S. 362 f.
(meine Hervorhebung!)
[220] J. M. Ziman:
Introduction, S. 9.
[221] Die Literatur
eines Fachgebietes stellt, wie Ziman
anschließend hervorhebt,
eine Sprache, einen Stil, eine Denkungsart
dar. So bedient sich die
moderne Physik hauptsächlich der englischen
Sprache bzw. eines
bestimmten "Jargons", sowie mathematischer
Symbole. Dies alles kann, so
Ziman, u.U. eine Verarmung durch den Verlust
sonstiger
Ausdrucksmöglichkeiten zur Folge haben.
[222] Vgl. N.
Henrichs: Informationswissenschaft und
Wissensorganisation.
[223] Vgl. K. Lenk:
Anforderungen der Kommunikationsgrundrechte
an die
Fachinformationsversorgung.
[224] Ebd. S. 6.
[225]
v.Vf.: Buchkultur im
Informationszeitalter.
[226] Vgl. T.D.C.
Kuch: Thematic Analysis in Information
Science:the Example of
"Literature Obscolescence".
[227] Vgl. K. Lenk,
J. Diekamnn, H. Schwab: Recht und Politik
der
Fachinformationsversorgung, S. 11 ff.
[228] Vgl. G.
Windel: Was ist Information und
Dokumentation? S. 9 ff.
[229] Vgl. W.D.
Garvey: Communication: The Essence of
Science.
[230] Ebd. S. 154.
[231] Vgl. F.W.
Lancaster: Information Retrieval Systems:
Characteristics, Testing and
Evaluation, S. 300 ff.
[232] Vgl. J.M.
Ziman: Introduction, S. 2; D.J. de Solla
Price: Little Science, Big
Science, S. 91: "We tend now to communicate
person to person instead of
paper to paper. In the most active areas we
diffuse knowledge through
collaboration."
[233] Vgl. K. Lenk:
Anforderungen der Kommunikationsgrundrechte.
[234] F.W.
Lancaster: Information Retrieval Systems, S.
306.
[235] Ebd. S. 309.
[236]
K. Lenk: Anforderungen der
Kommunikationsgrundrechte.
[237] Vgl. W.D.
Garvey: Communication; F.W. Lancaster:
Information Retrieval Systems,
S. 300 ff.
[238] Vgl. O. Nacke:
Informetrie: Ein neuer Name für eine neue
Disziplin; F. Narin,
J.K. Moll: Biblioimetrics; M.C. Drott, B.C.
Griffith: An Empirical
Examination of Bradford's Law and the
Scattering of Scientic
Literature; D. de S. Price: A General Theory
of Bibliometric and Other
Cumulative Advantage Processes, ders.:
Litttle Science, Big Science.
[239] Vgl. P. Zunde,
J. Gehl: Empirical Foundations of
Information Science; P. Zunde:
Empirical Laws and Theories of Information
and Software Sciences (der
Band 20 enthält die Beiträge zum ersten
"Symposium on
Empirical Foundations of Information and
Software Science", Georgia
Institute of Technology, Atlanta, November
1982).
[240] Vgl. R. Kuhlen
(Hrsg.): Datenbasen, Datenbanken, Netzwerke.
Bd.1, S. 15.
[241] Vgl. G.
Salton, M.J. McGill: Introduction to Modern
Information Retrieval, S. 7
ff.
[242] Vgl. L.C.
Smith: Artificial Intelligence: Applications
in Information Systems;
ders.: Artificial Intelligence: A Selected
Bibliography; R. Kuhlen: Zur
Lage der Künstlichen-Intelligenz-Forschung
in der Bundesrepublik
Deutschland. (Vgl. Ausblick)
[243] E. Oeser:
Wissenschaft und Information, S. 86.
[244] Eine DE geht
stellvertretend für eine DBE ein. Vgl. K.
Laisiepen u.a.:
Grundlagen, S. 106 ff.
[245] R. Kuhlen:
Linguistische Grundlagen, S. 728. Vgl. G.
Salton, M.J. McGill:
Introduction to Modern Information
Retrieval, S. 257 ff.
[246] E. Oeser:
Wissenschaft und Information, S. 86.
[247]
Encyklopédie ou Dictionnaire Raisonné des
Sciences, des
Arts et des Métiers. Par une société de gens
de
Lettress. Art. Encyclopédie.
[248] Ebd.:
"Une considération, surtout,
qu'il ne faut point perdre de vue, c'est que
si l'on bannit l'homme ou
l'être
pensant et
contemplateur de dessus la surface de la terre,
ce spectacle
pathétique et sublime de la nature n'est plus
qu'une
scène triste et muette. L'univers se tait; le
silence et la nuit
s'en emparent. Tout se change en une vaste
solitude où les
phénomènes inobservés se passent c'une
manière obscure et sourde. C'est la présence de
l'home
qui rend l'existence des êtres
intéressante."
[249] Vgl. I.
Dahlberg: Grundlagen universaler
Wissensordnung, S. 30 ff.
[250] B.C. Vickery:
Classification and Indexing in Science, s.
11.
[251] Vgl. N.
Rescher: Cognitive Systematization: A
System-theoretic approach to a
coherentist theory of knowledge, und die
Rezension von F. Suppe. Ferner
E. Oeser: Semantisch-pragmatische
Information und Ordnung des Wissens,
S. 29-48.
[252] Vgl. E.
Tugendhat: Vorlesungen zur Einführung in die
sprachanalytische
Philosoophie.
[253] N. Henrichs:
Gegenstandstheoretische Grundlagen der
Bibliotheksklassifikation?, S.
131.
[254] Vgl. I.
Dahlberg: Grundlagen universaler
Wissensordnung.
[255] Vgl. N.
Henrichs: Philosophische Dokumentation. Das
mit Düsseldorf
kooperierende "The Philosopher's Index"
(Ohio State University, USA)
benutzt ebenfalls keine Fachklassifkation.
[256] Ich
meine hiermit die Geschichte der modernen
Dokumentation. Die Methode
des "Indexierens" hat aber, unabhängig vom
Information Retrieval,
eine lange Geschichte. Vgl. M. Cornog: A
history of indexing technology.
[257] Vgl. H.H.
Wellish: "Index": the word, its history,
meanings and usages.
[258] G. Wersig:
Thesaurus-Leitfaden. Eine Einführung in das
Thesaurus-Prinzip in
Theorie und Praxis. Vgl. die Rezension von
D. Soergel.
[259] Vgl. H.
Kalverkämper: Die Axiomatik der
Fachsprachen-Forschung; H.J.
Schuck: Fachsprache und Gemeinsprache.
[260] Vgl. I.L.
Travis, R. Fidel: Subject Analysis, S. 143:
"Another clear pattern over
the past 20 or 30 years has been the shift
from thinking of different
retrieval techniques as opposing systems to
considering them as
complementary."
[261] V.W.
Lancaster: Information Retrieval Systems, S.
279 ff.
[262] Vgl. G.
Lustig: Weiterentwicklung der automatischen
Indexierung im Projekt AIR.
Solche Verfahren haben m.E. Aussicht auf
Erfolg sofern sie
hermeneutisch konzipiert sind, d.h. sofern
sie das (Vor-)Wissen eines
"erfahrenen Retrievers" zu integrieren
vermögen. Vgl. G. Knorz:
Automatisches Indexieren als Erkennen
abstrakter Objekte, S. 80 ff.
Über die Rolle von "Präsuppositionen" und
"Weltwissen" in
Zusammenhang mit Datenbanksystemen vgl. K.
Morik:
Überzeugungssysteme der künstlichen
Intelligenz, S.123 ff.
[263] G. Salton
u.a.: Introduction ot Modern Information
Retrieval.
[264] F.W.
Lancaster: Trends in Subject Indexing from
1957 to 2000.
[265] N. Henrichs:
Philosophische Dokumentation, S. 21.
[266] Vgl. N.
Henrichs, H. Rabanus: ALBUM –
ein
Verfahren für Literatur-Dokumentation.
[267] Vgl. N.
Henrichs: Benutzungshilfen für das
Retrieval, S. 158 f.
[268] Ebd.
[269] G. Fugmann:
Toward a Theory of Information Supply and
Indexing.
[270] G. Fugmann:
Toward a Theory of Information Supply;
ders.: On the Practice of
Indexing and its Theoretical Foundations.
[271] Vgl. B.
Endress-Niggemeyer: Referierregeln und
Referate –
Abstracting als regelgesteuerter
Textverarbeitungsprozeß; B.
Weßner: Inhaltsangaben zur Kurzorientierung.
[272] Vgl. H. Borko,
Ch.L. Bernier: Abstracting Concepts and
Methods.
[273] Vgl.
IAEA-INIS-4: Instructions for Submitting
Abstracts; Zentralstelle
für Psychologische Information und
Dokumentation (Universität
Trier) (Hrsg.): Leitfaden für die
inhaltliche Erschließung
von Zeitschriftenaufsätzen.
[274] Vgl. Cicero:
Topica II, 2; Th. Kisiel: Ars inveniendi: A
Classical Source for
Contemporary Philosophy of Science.
[275] Vgl. G.W.
Leibniz: Dissertatio de Arte Combinatoria.
Voraussetzung sind eine
"lingua characteristica" und ein "calculus
ratiocinator". In bezug auf
Th. Hobbes schreibt Leibniz: "merito posuit
omne opus mentis nostrae
esse computationem" (S. 194) Zum Verhältnis
Mensch-Maschine bei
Leibniz vgl. M. Schneider: Leibniz über
Geist und Maschine.
[276] G.W.
Leibniz: Discours touchant la méthode de la
certitude et l'art
d'inventer, Kap. LIV.
[277] Ebd.: "Je
suis obligé quelquefois de comparer nos
connoissances à
une
grande boutique ou magasin ou comptoir sans
ordre et sans inventaire;
car
nous ne savons pas nous mêmes ce que nous
possedons deja et ne
pouvons
pas nous en servir au besoin. Il y a une se
trouvant dans les auteurs,
mail il y en a encore bien plus, qui se
trouvent dispersées
parmi
les hommes dans la pratique de chaque
profession; et si le plus exquis
et le plus essentiel de tout cela se voyoit
recueilli et rangé
par
ordre avec plusieurs indices, propres à
trouver et à
employer
chaque chose là où elle peut servir, nous
admirerions
peut-être
nous mêmes nos richesses et plaindrions notre
aveuglement, d'en
avoir
si peu profité."
[278[ Eine ähnliche
begriffliche und
terminologische
Unterscheidung wird im Bereich der
"künstliche-Intelligenz-Forschung" zwischen
"heuristics" (Technik
zur Verbesserung der Effizienz eines
Suchprozesses) und "heuretics"
(das Wissen um die Suchkunst selbst) gemacht.
Vgl. E. Rich: Artificial
Intelligence, S. 35 ff.
[279] Im Deutschen sind die
Komposita:
Dialoggerät,
Dialotteilnehmerdienst, Dialog-Verkehr usw.
üblich. Vgl. K.
Laisiepen u.a.: Grundlagen der praktischen
Information und
Dokumentation. Im Englischen werden "online
retrieval system" auch als
"interactive" oder "conversational"
bezeichnet. Vgl. F.W. Lancaster:
Information Retrieval Systems, S. 70.
[280] Vgl. H.-G. Gadamer:
Wahrheit und Methode, S.
344 ff. (Vgl. II,2.c)
[281[ Vgl. E. Oeser:
Wissenschaft und Information, S.
68.
[282] Vgl. H.-G. Gadamer:
Wahrheit und
Methode, S. 365.
[283[ Vgl. E. Garfield: What
Are Facts (Data) and
What Is Information?,
der in diesem Zusammenhang auf den
etymologischen Ursprung des
Informationsbegriffs hinweist. Vgl. v.Vf.:
Information.
[284[ N.J: Belkin u.a.: ASK
for Information
Retrieval, S. 61 ff. (Vgl.
I,3,d)
[285[ Vgl. A. Diemer:
Elementarkurs Philosophie, S.
194. Ferner: C.P.R.
Dubois: The use of thesauri in online
retrieval.
[286] Vgl. A.N. Sommerville:
The Pre-Search Reference
Interview – A
Step by Step Guide; K. Markey: Levels of
question formulation in
negotiation of information need during the
online presearch interview.
[287] D.R. Swanson:
Information Retrieval as a
Trial-and-Error Process.
[288] S.P. Harter:
Scientific Inquiry: A Model for
Online Searching.
[289] Vgl. M.H. Heine: The
"question" as a
fundamental variable
in information science.
[290] Vgl. H. Brooks, R.N.
Ody, N.J. Belkin:
Representing and
classifying anomalous states of knowledge.
(Vgl. I,3,d)
[291] Vgl. W.M. Henry, J.A.
Leigh, L.A. Tedd, P.W.
Williams: Online
Searching. An Introduction; C.H. Fenichel,
Th.H. Hogan: Online
Searching: A Primer; G. Byerly: Online
Searching. A Dictionary and
Bibliographic Guide.
[292] Vgl. D.T. Hawkins, R.
Wagers: Online
Bibliographic Search
Strategy Development; M.J. Bates: Information
Search Tactics; R.E.
Hoover: Online Search Strategies; R.
Fidel: Online Searching
Styles: A Case-Study-Based Model of Searching
Behavior.
[293] M.J. Bates, Idea
Tactics.
[294] C.W. Cleverdon:
Optimierung von
Online-Informationsdienstleistungen in
Wissenschaft und Technik.
[295] Ebd. Vgl. I. Wormell:
Cognitive aspects in
natural language and
free-text searching, der die Bedeutung
verobjektivierter
Wissensstrukturen bei der (online) Suche
hervorhebt.
[296] G. Salton u.a.
Introduction to Modern
Information Retrieval, S.
161. Vgl. die klassische Erörterung des
Relevanzbegriffs im
Bereich der Informationswissenschaft von T.
Saracevic: Relevance. A
Review of the Literature and a Framework for
Thinking on the Notion in
Information Science.
[297] Vgl. M. Möhr:
Benutzerorientierte
Bewertung von
Information-Retrieval-Systemen. Ferner G.
Salton u.a.: Introduction to
Modern Information Retrieval, S. 176.
[298] D.R. Swanson:
Information Retrieval as a
Trial-and-Error Process
[299] F.W. Lancaster:
Information Retrieval Systems,
S. 265-272.
[300[ G. Salton u.a.:
Introduction to Modern
Information Retrieval, S.
163.
[301[ Vgl. D.R. Swanson:
Information Retrieval as a
Trial-and-Error
Process; M.K. Buckland: Relatedness, Relevance
and Responsiveness in
Retrieval Systems; B. Boyce: Beyond
Topicality; D.A. Kemp: Relevance,
Pertinence and Information System Development;
P. Wilson: Situational
Relevance.
[302] M. Möhr:
Benutzerorientierte Bewertung.
[303] F.W. Lancaster:
Information Retrieval Systems,
S. 264:
"Pertinence decisions, then, are very
transient, much more so than
relevance decisions. They are influenced by
both the passage of time
and the sequence in which the decisions are
made."
[304[ G. Salton u.a.:
Introduction to Modern
Information Retrieval, S.
176 f.
[305] Vgl. M. Möhr:
Benutzerorientierte
Bewertung; D. Ellis:
Theory and explanation in information
retrieval research, der die
Bedeutung "behavioristischer" Nutzer-Quellen
Analysen (anstelle einer
isolierten Betrachtung subjektiver
Wissensstrukturen) hervorhebt.
[306] A. Schütz: Reflections
on the Problem of
Relevance. Die von
Schütz erörterten Relevanzarten, nämlich
"topische",
"motivierte" und "interpretative" Relevanz,
weisen jeweils auf den
thematischen Horizont des Fragenden, auf
seinen Erwartungshorizont
sowie auf den Bewertungsprozeß hin,
wodurch er die
"Pertinenz" der Antworten thematisch und
"zweckmäßig"
analysiert und somit zur Bildung eines neuen
Horizontes kommt.
[307] Vgl. S. Nora, A. Minc:
Die Informatisierung der
Gesellschaft, S.
119 bis 130. Die von den Autoren angesprochene
"Sozialisierung der
Information", im Sinne eines Mechanismus zur
Harmonisierung von Staat
und Gesellschaft, geht über die hier zu
behandelnde Frage hinaus.
Dennoch spielt die Fachinformation, bedingt
durch die "Telematik", auch
in jenem Sozialisierungsprozeß eine nicht zu
unterschätzende
Rolle.
[308] Y. Masuda: The
Information Society as
Post-Industrial-Society.
[309] D. Bell: The Social
Framework of the
Information Society.
[310] J: Weizenbaum: Once
More: The Computer
Revolution; ders.:
Computer Power and Human Reason. Ferner die
"Reviews" von B.G.
Buchanan, J. Lederberg, J.McCarthy: Three
Reviews of J. Weizenbaum's
Computer Power and Human Reason.
[311] J. Weizenbaum: Once
More, S. 457: "Who is the
beneficiary of our so much-advertised
technological progress and who
are its victims? What limits ought we, the
people generally and
scientists and engineers particularly, to
impose on the application of
computation to human affairs? What is the
impact of the computer [...]
on the self-image of human beings and on human
dignity?"
[312] Vgl.
Kommunikative Gesellschaft: Beiträge einer
interkulturellen Tagung
zwischen Japanern und Europäern.
[313] Vgl. M.
Kochen: Information and Society.
[314] Vgl. N.
Henrichs: Sozialisation der Information; G.
Vowe: Information und
Kommunikation, S. 368 ff.; G. Wersig:
Informationssoziologie.
[315] Vgl. v.V.:
Moral issues in information science.
[316] N. Henrichs:
Sozialisation der Information.
[317] G.
Rózsa: Scientific Information and Society.
[318] Auf die
möglichen faktischen Einschränkungen dieser
Publizität
werde ich im dritten Abschnitt dieses
Kapitels hinweisen. Zur Frage des
Datenschutzes vgl. G. Runge, R. Capurro:
Ethische Reflexionen zum
Datenschutz. Zur Unerläßlichkeit der
ungehinderten
Mitteilung aller Ergebnisse und Meinungen
für das Gedeihen der
Wissenschaft sowie zur Erhaltung
bürgerlicher Freiheiten vgl. A.
Einstein: Aus meinen späten Jahren, S. 52
ff., 176, 199 f.
[319] K. Lenk:
Anforderungen der Kommunikationsgrundrechte
an die
Fachinformationsversorgung, S. 14.
[320] Vgl. Ch.
Oppenheim: Data Banks and Democracy.
[321] K. Lenk:
Anforderungen der Kommunikationsgrundrechte,
S. 19.
[322] Vgl. v.Vf.
Buchkultur im Informationszeitalter.
[323] Vgl. S.
Artandi: Man, Information, and Society: New
Patterns of Interaction; J.
Bowen: Computers and information for the
citizen. What is missing?
Where are the gaps?, R.W. Swanson: The
Information Business is People
Business.
[324] Vgl. D.R.
Dolan: Databases for Everyman.
[325] Ebd. S. 104:
"The move toward user-friendly systems is
essentially a democratic
trend which gives information power to the
people. Online systems are
no longer in teh hands of online gatekeeprs,
but are in the hands of
the masses. But do these systems have mass
appeal? Offering scholarly
information on a menu-driven system hardly
constitutes user-friendly.
Not until we have databases which are of,
by, and for the people will
the present systems be truly user-friendly."
Vgl. M. Kochen (Hrsg.):
Information for Action. From Knowledge to
Wisdom.
[326] Zitat bei F.W.
Lancaster: Information Retrieval Systems, S.
324: "An information
retrieval system will tend not to be used
wherever it is more painful
and troublesome for a customer to have
information that for him not to
have it."
[327] D. Ihde:
Technics and Praxis, S. 3 ff.
[328] Der Ausdruck
"computer literacy" wurde wahrscheinlich auf
der 1981 in Lausanne
(Schweiz) abgehaltenen Konferenz über
"Computers in Education" vom
amerikanischen Wissenschaftler A.P. Ershov
erstmalig gebraucht. Zum
Umfang dieses Begriffs, der von der
Fähigkeit mit dem Computer
umzugehen bis hin zur kritischen Betrachtung
von "science
fiction"-Visionen reicht, vgl. Diebold
Management Report: "Computer
literaca". Ferner Sh. Turkle: The Second
Self. Computers and the Human
Spirit, die die Art und Weise wie der Umgang
mit dem Computer auf
Menschen wirkt und zur Entstehung einer
"computer culture" führt,
soziologisch und psychologisch analysiert.
Zum letzteren Gesichtspunkt
vgl. die Rezension zu Turkles Buch von S.
Zizek: Un lapsus
anti-totalitaire?
[329] Vgl. F.W.
Lancaster: The Evolving Paperless Society
and its Implications for
Libraries. Kritisch dazu Ch. Oppenheim: New
Technology: Trends, Limits
and Social Effects.
[330]
F.W. Lancaster: The Future of
Indexing and Abstracting Services.
[331] Vgl. B.
Vickery, R. Heseltine, C. Brown: Interactive
Information Networks and
UK Libraries; K.J. McGarry: The Changing
Context of Information; J:H.
Shera: Knowing Books and Men; Knowing
Computers, Too.
[332] Vgl. K. Lenk:
Fachinformationsversorgung im Zeichen
technischen Wandelns.
[333] Vgl. G. Salton
u.a.: Introduction to Modern Information
Retrieval, S. 410 ff.
[334] K. Ganzhorn:
Informatik im Übergang (meine
Hervorhebung!). Zur Bedeutung von
Sprache und Intersubjektivität bei der
Gestaltung einer "sanften"
Informationstechnik sowie einer humanen
"Informationsgesellschaft" vgl.
K. Ezawa: Japans Weg in eine
Informationsgesellschaft.
[335] G. Wersig:
Informations- und
Kommunikationstechnologien: Ersatz oder
Unterstützung der menschlichen Komponente?
Eine einseitige
Formalisierung von Kommunikationsprozessen
kann negative Folgen haben
z.B. für "junge Disziplinen" oder auch für
den
Innovationsprozeß. Vgl. W. Dijkhuis: An
anatomy of innovation, S.
186.
[336] Vgl. G.
Hottois: Le signe et la technique. La
philosophie à
l'épreuve de la technique. Dazu v.Vf.:
Technics, Ethics,and the
Question of Phenomenology. Ferner H. Lenk:
Zur Sozialphilosophie der
Technik; F. Rapp, P.T. Durbin (Hrsg.):
Technikphilosophie in der
Diskussion.
[337] UNESCO
Intergovernmental conference on scientific
and technological
information for development. UNISIST II.
Final Report.
[338] Diese
"Barrieren" lassen sich auch
fachgebietsspezifisch untersuchen. Vgl.
E.M. Vedernikova: Information Barriers in
Industry.
[339] M.J.
Menou: Cultural barriers to the international
transfer of information.
[340] Vgl. J. Michel:
Linguistic and political barriers in the
international transfer of
information in science and technology;
V. Rosenberg: Cultural and
political traditions and their impact on
the transfer and use of
scientifica information.
[341] Vgl. J. Davies:
Linguistic and political
barriers in the international transfer
of information in science and
technology: A reinterpretation.
[342] Vgl. G.
Cochrane, P. Atherton: The Cultural
Appraisal of Efforts to Allevaite
Information Inequity; A. Neelameghan:
Some Issues in Information Transfer: A
Third World Perspective; H.
East: Information Technology and the
Problems of Less Developed
Countries.
[343] Vgl.
F. Krückeberg: Kommunikative
Gesellschaft und interkulturelle
Begegnung; U. Kalbhen, F. Krückeberg, J.
Reese (Hrs.):
Gesellschaftliche Auswirkungen der
Informationstechnologie; R.L.
Chartrand, J.W. Morentz (Hrsg.):
Information Technology Serving Society.
[344] Vgl. G. Wersig:
Das Kreuz der Fachinformation:
Esoterik,
Marginalie, Magie oder wohin?
[345] Aus der
umfangreichen Literatur zum Thema
"Philosophie und künstliche Intelligenz"
vgl. auf der einen Seite
M. Boden: Artificial Intelligence and
Natural Man; A. Sloman: The
Computer Revolution in Philosophy, sowie
D.R. Hofstadter: Gödel,
Escher, Bach, die auf die Tragweite des
KI-Ansatzes als Modell des
menschlichen "Geistes" hinweisen,
während auf der anderen Seite
H.L. Dreyfus: Die Grenzen künstlicher
Intelligenz; J. Weizenbaum:
Computer Power and Human Reason; ders.:
Once More: The Computer
Revolution, auf die Grenzen dieses
Ansatzes aufmerksam machen. Vgl.
auch J. Haugeland (Hrsg.): Mind Design;
M. Ringle (Hrsg.):
Philosophical Perspectives in Artificial
Intelligence. Zum Thema
"künstliche Intelligenz Forschung und
ihre epistemologische
Grundlagen" vgl. die gleichnamige
Darstellung von W. Daiser. Zur
Entwicklung und Anwendung der
KI-Forschung vgl. SEAI Institute:
Artificial Intelligence: A New Tool for
Industry.
[346] Vgl. M.
Tietzel: L'Homme machine.
Künstliche Menshen in Philosophie,
Mechanik und Literatur,
betrachtet aus der Sicht der
Wissenschaftstheorie. Der Autor hebt die
Bedeutung menschlicher
"Hintergrundwissen" hervor.
[347] Zum Thema
"Denken und Computer" vgl. den
klassischen Ansatz von M. Bunge: Do
Computers Think? Ferner B.
Waldenfels: Mens sive cerebrum.
Intentionalität in
mentalistischer Sicht; A. Baruzzi:
Mensch und Maschine. Das Denken sub
specie machinae. Nach W.
Stegmüller: Neue Wege der
Wissenschaftsphilosophie (S. 21), werden
wir niemals über ein
vollständiges Erklärungsmodell für den
Menschen
verfügen (andernfalls, hätten wir uns in
eine neue Spezies
transformiert), d.h. wir sind für uns
selbst nicht transparent.
Heidegger pflegte zu sagen, das Leben
sei "diesig". Vgl. M. Heidegger:
Phänomenologische Interpretationen zu
Aristoteles, S. 88.
[348] F. Nietzsche:
Unzeitgemäße
Betrachtungen, S. 326.
Literaturverzeichnis
Folgende in diesem Literatuverzeichnis
zitierten
Arbeiten des
Verfassers sind online zugänglich:
- Information
(1978)
- Heidegger
über
Sprache und Information (1981)
- Zur
Frage der Ethik
in Fachinformation und -kommunikation
(1981)
- Zur Kritik von K.R. Poppers platonistischem
Modell des Wissens (1983)
(Siehe Kap.
II,1,c dieser Schrift)
- Moral
issues in
information science (1985)
- Epistemology
and
information science (1985)
- Technics,
Ethics and
the Question of Phenomenology (1985)






















Letzte
Änderung: 1 Oktober 2024